elasticsearch 快照
参考官方文档 需要配置共享存储,并创建快照仓库,之后才能创建快照
1. 设置共享存储(NFS)
安装nfs及其配置
1
2
3
4
5
6
|
yum install nfs-utils -y
cat /etc/exports
/data/elastic_backup 192.168.1.*(rw,sync,all_squash)
chmod 777 elastic_backup
systemctl start nfs
|
all_squash 表示客户机写入nfs的数据全部映射为nobody用户
这里设置 all_squash并把目录设置为777 是为防止elasticsearch 集群的每个节点启动的uid和gid 不一致导致在创建快照仓库时无法创建成功。
在这里说明下,并不是要求elasticsearch集群中中每个节点启动的用户id和group id 必须是一致的 只要写入的文件是同一个用户即可,所以这里设置all_squash
2. 挂载nfs
1
2
3
|
yum install nfs-utils # 安装nfs工具
mkdir /data/es_snapshot
mount -t nfs nfs-server-ip:/data/elastic_backup /data/es_snapshot
|
3. elasticsearch 修改配置
在elasticsearch.yml文件中增以下配置,并重启elasticsearch
1
|
path.repo: ["/data/es_snapshot"]
|
其实如果在已有数据的elasticsearch集群中配置此项,并且数据量比较大的集群中,需要一台一台的重启数据,在重启之用需要把数据同步关闭,如下指令:
1
|
curl -XPUTlocalhost:9200/_cluster/settings -d'{"transient":{"cluster.routing.allocation.disable_allocation":true}}'
|
重启完成后需要打开数据同步,并等待数据同步完成后再继续下一个节点
1
|
curl -XPUTlocalhost:9200/_cluster/settings -d'{"transient":{"cluster.routing.allocation.disable_allocation":false}}'
|
4. 创建仓库
使用指令如下:
1
2
3
4
5
6
7
8
9
10
|
#创建仓库
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/data/es_snapshot"
}
}
# 查看仓库
GET /_snapshot/my_backup
|
如果你是使用了Cerebro 那你可以在这里面进行直接创建仓库, 如下所示:
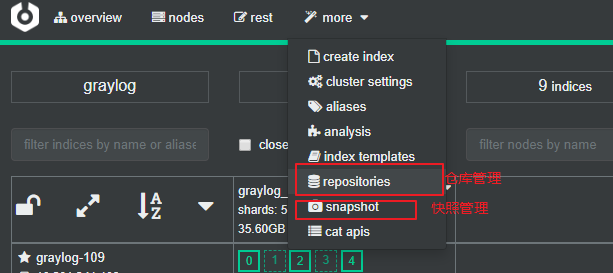
创建仓库
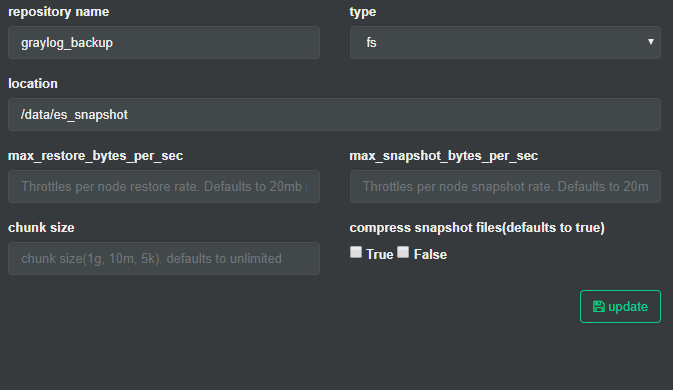
创建完成后
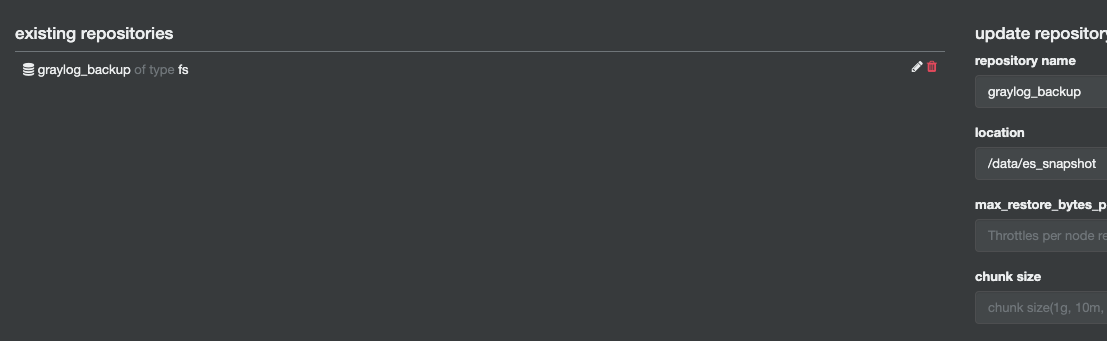
在快照管理中可以查看已有的快照和创建快照的入口
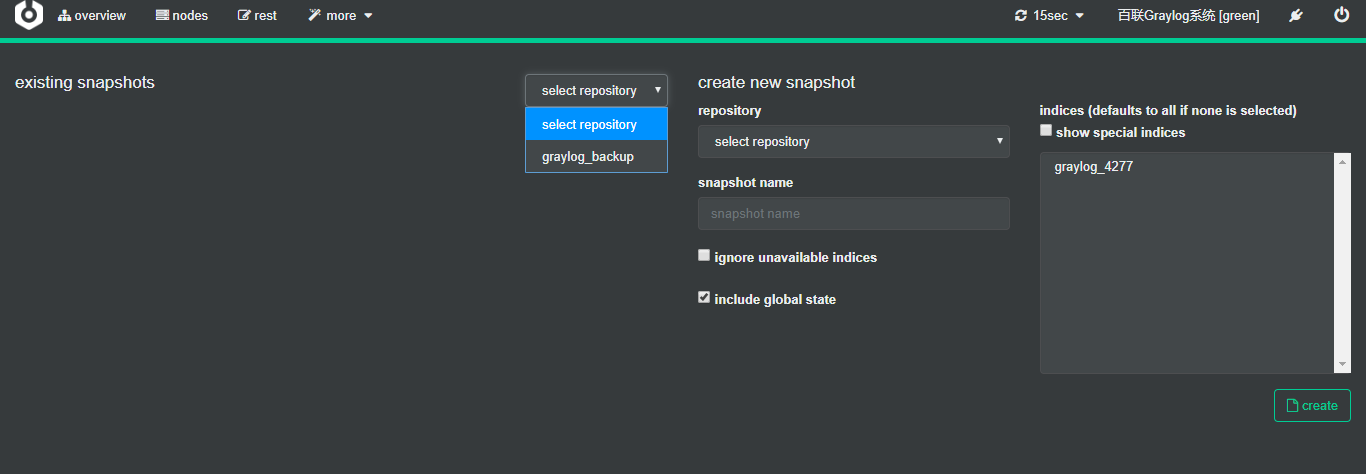
创建快照指令如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# 创建快照
PUT /_snapshot/my_backup/snapshot_1?wait_for_completion=true
{
"indices": "index_1,index_2", # 指定索引名称
"ignore_unavailable": true,
"include_global_state": false,
"metadata": {
"taken_by": "kimchy",
"taken_because": "backup before upgrading"
}
}
# 查看快照
GET /_snapshot/my_backup/snapshot_1
|
5. 数据恢复
如果在不同集群恢复,需要把nfs共享过去并同样的配置好repo.path即可使用快照。
使用页面
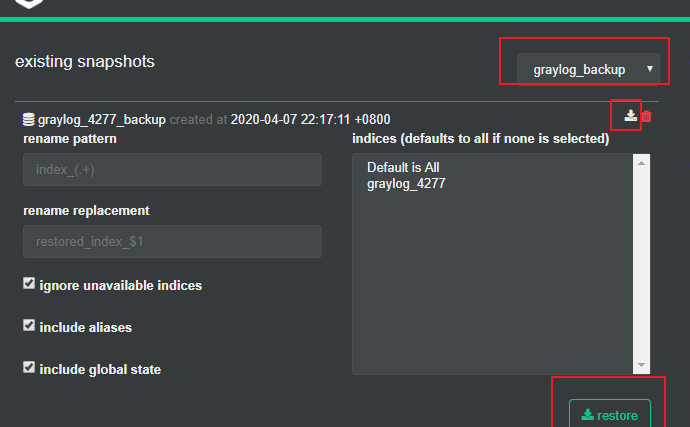
使用指令:
1
2
3
4
5
6
7
8
|
POST /_snapshot/my_backup/snapshot_1/_restore
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": true,
"rename_pattern": "index_(.+)",
"rename_replacement": "restored_index_$1"
}
|
指令中的相关参数可以参考官方文档